Нормальное распределение случайной величины и правило трех сигм. Нормальный закон распределения вероятностей Нормальное случайное распределение
Рассмотрим частный случай, когда параметры распределения m = 0 .σ = 1 . Нормальное распределение N(0;1) называется стандартным нормальным распределением. В этом случае плотность распределения
(22)
Кривая распределения, построенная по формуле стандартного нормального распределения имеет колоколообразныи вид, вертикальная ось является осью симметрии, горизонтальная - асимптотой. Максимальное значение ординаты равно
При значениях аргумента х = ± 3 значения функции близки к нулю: при общей площади под кривой распределения, равной единице, в этом диапазоне лежит 99,73%. Заметим, что в диапазоне х = ± 2 лежит 95,44% площади под кривой распределения, а в диапазоне х = ±1 - 68,26%.

Рисунок 3.- Кривая стандартного нормального распределения
При изменении параметра т график сдвигается вправо или влево так, что прямая х= т - ось симметрии

Рисунок 4- Влияние параметра т на вид кривой нормального распределения
При увеличении параметра σ максимум кривой распределения снижается, при уменьшении, а кривая вытягивается вверх, при этом по условию нормировки площадь под кривой распределения остается постоянной (и равной единице)

Рисунок 5 – Влияние параметра σ на вид кривой нормального распределения.
Вновь рассмотрим стандартное нормальное распределение N(0,1). Функция такого распределения иногда называется функцией Лапласа, она имеет специальное обозначение Ф(х).Можно записать уравнение
![]() (23)
(23)
Эnа функция табулирована. Например, Ф(2,48) = = 0,9934. График функции показан на рис.

Рисунок 6 - График функции стандартного нормального распределения
Из симметрии графика вытекает соотношение
Ф(-х) = 1-Ф(х)
Табулированы и квантили нормального распределения
Квантиль нормального распределения порядка р - это число u p , для которого Ф(u p) = p .Например,=1,645
Из симметрии графика функции стандартного нормального распределения и формулы вытекает полезное соотношение для квантилей:
u 1- p = u p
Можно установить связь между функцией распределения F(x) для распределения N(m,σ) и функцией стандартного нормального распределения:
![]() (24)
(24)
Вероятность попадания нормально распределенной случайной величины в интервал от x 1 до x 2 определяется по формуле
Часто в расчетах надо найти вероятность того, что случайная величина Х не слишком сильно отклонится от своего математического ожидания m:
Правило «трех сигм»
Пусть, например ε = 3σ. Используя таблицы функции стандартного нормального распределения найдем:
поэтому вероятность того, что случайная величина отклонится от математического ожидания больше, чем на Зσ, ничтожно мала:
Такое событие практически невозможно. В связи с этим на практике часто используется так называемое правило «трех сигм» : отклонение нормально распределенной случайной величины от ее математического ожидания, как правило, не превышает утроенного стандартного отклонения.
Рассмотрим применение свойств нормального распределения
Пример.1 На станке-автомате изготавливаются валики номинальным диаметром 10 мм. Стандартное отклонение, характеризующее точность станка, составляет σ = 0,03 мм. Сколько в среднем валиков из ста удовлетворяют стандарту, если для этого требуется, чтобы диаметр отклонялся от номинального не более чем на 0,05 мм?
Будут и задачи для самостоятельного решения, к которым можно посмотреть ответы.
Нормальное распределение: теоретические основы
Примерами случайных величин, распределённых по нормальному закону, являются рост человека, масса вылавливаемой рыбы одного вида . Нормальность распределения означает следующее : существуют значения роста человека, массы рыбы одного вида, которые на интуитивном уровне воспринимаются как "нормальные" (а по сути - усреднённые), и они-то в достаточно большой выборке встречаются гораздо чаще, чем отличающиеся в бОльшую или меньшую сторону.
Нормальное распределение вероятностей непрерывной случайной величины (иногда - распределение Гаусса) можно назвать колоколообразным из-за того, что симметричная относительно среднего функция плотности этого распределения очень похожа на разрез колокола (красная кривая на рисунке выше).
Вероятность встретить в выборке те или иные значение равна площади фигуры под кривой и в случае нормального распределения мы видим, что под верхом "колокола", которому соответствуют значения, стремящиеся к среднему, площадь, а значит, вероятность, больше, чем под краями. Таким образом, получаем то же, что уже сказано: вероятность встретить человека "нормального" роста, поймать рыбу "нормальной" массы выше, чем для значений, отличающихся в бОльшую или меньшую сторону. В очень многих случаях практики ошибки измерения распределяются по закону, близкому к нормальному.
Остановимся ещё раз на рисунке в начале урока, на котором представлена функция плотности нормального распределения. График этой функции получен при рассчёте некоторой выборки данных в пакете программных средств STATISTICA . На ней столбцы гистограммы представляют собой интервалы значений выборки, распределение которых близко (или, как принято говорить в статистике, незначимо отличаются от) к собственно графику функции плотности нормального распределения, который представляет собой кривую красного цвета. На графике видно, что эта кривая действительно колоколообразная.
Нормальное распределение во многом ценно благодаря тому, что зная только математическое ожидание непрерывной случайной величины и стандартное отклонение, можно вычислить любую вероятность, связанную с этой величиной.
Нормальное распределение имеет ещё и то преимущество, что один из наиболее простых в использовании статистических критериев, используемых для проверки статистических гипотез - критерий Стьюдента - может быть использован только в том случае, когда данные выборки подчиняются нормальному закону распределения.
Функцию плотности нормального распределения непрерывной случайной величины можно найти по формуле:
 ,
,
где x - значение изменяющейся величины, - среднее значение, - стандартное отклонение, e =2,71828... - основание натурального логарифма, =3,1416...
Свойства функции плотности нормального распределения
Изменения среднего значения перемещают кривую функции плотности нормального распределения в направлении оси Ox . Если возрастает, кривая перемещается вправо, если уменьшается, то влево.
Если меняется стандартное отклонение, то меняется высота вершины кривой. При увеличении стандартного отклонения вершина кривой находится выше, при уменьшении - ниже.
Вероятность попадания значения нормально распределённой случайной величины в заданный интервал
Уже в этом параграфе начнём решать практические задачи, смысл которых обозначен в заголовке. Разберём, какие возможности для решения задач предоставляет теория. Отправное понятие для вычисления вероятности попадания нормально распределённой случайной величины в заданный интервал - интегральная функция нормального распределения.
Интегральная функция нормального распределения :
 .
.
Однако проблематично получить таблицы для каждой возможной комбинации среднего и стандартного отклонения. Поэтому одним из простых способов вычисления вероятности попадания нормально распределённой случайной величины в заданный интервал является использование таблиц вероятностей для стандартизированного нормального распределения.
Стандартизованным или нормированным называется нормальное распределение , среднее значение которого , а стандартное отклонение .
Функция плотности стандартизованного нормального распределения :
![]() .
.
Интегральная функция стандартизованного нормального распределения :
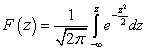 .
.
На рисунке ниже представлена интегральная функция стандартизованного нормального распределения, график которой получен при рассчёте некоторой выборки данных в пакете программных средств STATISTICA . Собственно график представляет собой кривую красного цвета, а значения выборки приближаются к нему.

Для увеличения рисунка можно щёлкнуть по нему левой кнопкой мыши.
Стандартизация случайной величины означает переход от первоначальных единиц, используемых в задании, к стандартизованным единицам. Стандартизация выполняется по формуле
На практике все возможные значения случайной величины часто не известны, поэтому значения среднего и стандартного отклонения точно определить нельзя. Их заменяют средним арифметическим наблюдений и стандартным отклонением s . Величина z выражает отклонения значений случайной величины от среднего арифметического при измерении стандартных отклонений.
Открытый интервал
Таблица вероятностей для стандартизированного нормального распределения, которая есть практически в любой книге по статистике, содержит вероятности того, что имеющая стандартное нормальное распределение случайная величина Z примет значение меньше некоторого числа z . То есть попадёт в открытый интервал от минус бесконечности до z . Например, вероятность того, что величина Z меньше 1,5, равна 0,93319.
Пример 1. Предприятие производит детали, срок службы которых нормально распределён со средним значением 1000 и стандартным отклонением 200 часов.
Для случайно отобранной детали вычислить вероятность того, что её срок службы будет не менее 900 часов.
Решение. Введём первое обозначение:
Искомая вероятность.
Значения случайной величины находятся в открытом интервале. Но мы умеем вычислять вероятность того, что случайная величина примет значение, меньшее заданного, а по условию задачи требуется найти равное или большее заданного. Это другая часть пространства под кривой плотности нормального распределения (колокола). Поэтому, чтобы найти искомую вероятность, нужно из единицы вычесть упомянутую вероятность того, что случайная величина примет значение, меньше заданного 900:
Теперь случайную величину нужно стандартизировать.
Продолжаем вводить обозначения:
z = (X ≤ 900) ;
x = 900 - заданное значение случайной величины;
μ = 1000 - среднее значение;
σ = 200 - стандартное отклонение.
По этим данным условия задачи получаем:
![]() .
.
По таблицам стандартизированной случайной величине (границе интервала) z = −0,5 соответствует вероятность 0,30854. Вычтем ее из единицы и получим то, что требуется в условии задачи:
Итак, вероятность того, что срок службы детали будет не менее 900 часов, составляет 69%.
Эту вероятность можно получить, используя функцию MS Excel НОРМ.РАСП (значение интегральной величины - 1):
P (X ≥900) = 1 - P (X ≤900) = 1 - НОРМ.РАСП(900; 1000; 200; 1) = 1 - 0,3085 = 0,6915.
О расчётах в MS Excel - в одном из последующих параграфах этого урока.
Пример 2. В некотором городе среднегодовой доход семьи является нормально распределённой случайной величиной со средним значением 300000 и стандартным отклонением 50000. Известно, что доходы 40 % семей меньше величины A . Найти величину A .
Решение. В этой задаче 40 % - ни что иное, как вероятность того, что случайная величина примет значение из открытого интервала, меньшее определённого значения, обозначенного буквой A .
Чтобы найти величину A , сначала составим интегральную функцию:
![]()
По условию задачи
μ = 300000 - среднее значение;
σ = 50000 - стандартное отклонение;
x = A - величина, которую нужно найти.
Составляем равенство
![]() .
.
По статистическим таблицам находим, что вероятность 0,40 соответствует значению границы интервала z = −0,25 .
Поэтому составляем равенство
![]()
и находим его решение:
A = 287300 .
Ответ: доходы 40 % семей менее 287300.
Закрытый интервал
Во многих задачах требуется найти вероятность того, что нормально распределённая случайная величина примет значение в интервале от z 1 до z 2 . То есть попадёт в закрытый интервал. Для решения таких задач необходимо найти в таблице вероятности, соответствующие границам интервала, а затем найти разность этих вероятностей. При этом требуется вычитать меньшее значение из большего. Примеры на решения этих распространённых задач - следующие, причём решить их предлагается самостоятельно, а затем можно посмотреть правильные решения и ответы.
Пример 3. Прибыль предприятия за некоторый период - случайная величина, подчинённая нормальному закону распределения со средним значением 0,5 млн. у.е. и стандартным отклонением 0,354. Определить с точностью до двух знаков после запятой вероятность того, что прибыль предприятия составит от 0,4 до 0,6 у.е.
Пример 4. Длина изготавливаемой детали представляет собой случайную величину, распределённую по нормальному закону с параметрами μ =10 и σ =0,071 . Найти с точностью до двух знаков после запятой вероятность брака, если допустимые размеры детали должны быть 10±0,05 .
Подсказка: в этой задаче помимо нахождения вероятности попадания случайной величины в закрытый интервал (вероятность получения небракованной детали) требуется выполнить ещё одно действие.

позволяет определить вероятность того, что стандартизованное значение Z не меньше -z и не больше +z , где z - произвольно выбранное значение стандартизованной случайной величины.
Приближенный метод проверки нормальности распределения
Приближенный метод проверки нормальности распределения значений выборки основан на следующем свойстве нормального распределения: коэффициент асимметрии β 1 и коэффициент эксцесса β 2 равны нулю .
Коэффициент асимметрии β 1 численно характеризует симметрию эмпирического распределения относительно среднего. Если коэффициент асимметрии равен нулю, то среднее арифметрического значение, медиана и мода равны: и кривая плотности распределения симметрична относительно среднего. Если коэффициент асимметрии меньше нуля (β 1 < 0 ), то среднее арифметическое меньше медианы, а медиана, в свою очередь, меньше моды () и кривая сдвинута вправо (по сравнению с нормальным распределением) . Если коэффициент асимметрии больше нуля (β 1 > 0 ), то среднее арифметическое больше медианы, а медиана, в свою очередь, больше моды () и кривая сдвинута влево (по сравнению с нормальным распределением) .
Коэффициент эксцесса β 2 характеризует концентрацию эмпирического распределения вокруг арифметического среднего в направлении оси Oy и степень островершинности кривой плотности распределения. Если коэффициент эксцесса больше нуля, то кривая более вытянута (по сравнению с нормальным распределением) вдоль оси Oy (график более островершинный). Если коэффициент эксцесса меньше нуля, то кривая более сплющена (по сравнению с нормальным распределением) вдоль оси Oy (график более туповершинный).
Коэффициент асимметрии можно вычислить с помощью функции MS Excel СКОС. Если вы проверяете один массив данных, то требуется ввести диапазон данных в одно окошко "Число".

Коэффициент эксцесса можно вычислить с помощью функции MS Excel ЭКСЦЕСС. При проверке одного массива данных также достаточно ввести диапазон данных в одно окошко "Число".

Итак, как мы уже знаем, при нормальном распределении коэффициенты асимметрии и эксцесса равны нулю. Но что, если мы получили коэффициенты асимметрии, равные -0,14, 0,22, 0,43, а коэффициенты эксцесса, равные 0,17, -0,31, 0,55? Вопрос вполне справедливый, так как практически мы имеем дело лишь с приближенными, выборочными значениями асимметрии и эксцесса, которые подвержены некоторому неизбежному, неконтролируемому разбросу. Поэтому нельзя требовать строгого равенства этих коэффициентов нулю, они должны лишь быть достаточно близкими к нулю. Но что значит - достаточно?
Требуется сравнить полученные эмпирические значения с допустимыми значениями. Для этого нужно проверить следующие неравенства (сравнить значения коэффициентов по модулю с критическими значениями - границами области проверки гипотезы).
Для коэффициента асимметрии β 1 .
В статье подробно показано, что такое нормальный закон распределения случайной величины и как им пользоваться при решении практически задач.
Нормальное распределение в статистике
История закона насчитывает 300 лет. Первым открывателем стал Абрахам де Муавр, который придумал аппроксимацию еще 1733 году. Через много лет Карл Фридрих Гаусс (1809 г.) и Пьер-Симон Лаплас (1812 г.) вывели математические функции.
Лаплас также обнаружил замечательную закономерность и сформулировал центральную предельную теорему (ЦПТ ), согласно которой сумма большого количества малых и независимых величин имеет нормальное распределение.
Нормальный закон не является фиксированным уравнением зависимости одной переменной от другой. Фиксируется только характер этой зависимости. Конкретная форма распределения задается специальными параметрами. Например, у = аx + b – это уравнение прямой. Однако где конкретно она проходит и под каким наклоном, определяется параметрами а и b . Также и с нормальным распределением. Ясно, что это функция, которая описывает тенденцию высокой концентрации значений около центра, но ее точная форма задается специальными параметрами.
Кривая нормального распределения Гаусса имеет следующий вид.
График нормального распределения напоминает колокол, поэтому можно встретить название колоколообразная кривая . У графика имеется «горб» в середине и резкое снижение плотности по краям. В этом заключается суть нормального распределения. Вероятность того, что случайная величина окажется около центра гораздо выше, чем то, что она сильно отклонится от середины.

На рисунке выше изображены два участка под кривой Гаусса: синий и зеленый. Основания, т.е. интервалы, у обоих участков равны. Но заметно отличаются высоты. Синий участок удален от центра, и имеет существенно меньшую высоту, чем зеленый, который находится в самом центре распределения. Следовательно, отличаются и площади, то бишь вероятности попадания в обозначенные интервалы.
Формула нормального распределения (плотности) следующая.
![]()
Формула состоит из двух математических констант:
π – число пи 3,142;
е – основание натурального логарифма 2,718;
двух изменяемых параметров, которые задают форму конкретной кривой:
m – математическое ожидание (в различных источниках могут использоваться другие обозначения, например, µ или a );
σ 2 – дисперсия;
ну и сама переменная x , для которой высчитывается плотность вероятности.
Конкретная форма нормального распределения зависит от 2-х параметров: (m ) и (σ 2 ). Кратко обозначается N(m, σ 2) или N(m, σ) . Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ 2 характеризует размах вариации, то есть «размазанность» данных.
Параметр математического ожидания смещает центр распределения вправо или влево, не влияя на саму форму кривой плотности.

А вот дисперсия определяет остроконечность кривой. Когда данные имеют малый разброс, то вся их масса концентрируется у центра. Если же у данных большой разброс, то они «размазываются» по широкому диапазону.

Плотность распределения не имеет прямого практического применения. Для расчета вероятностей нужно проинтегрировать функцию плотности.
Вероятность того, что случайная величина окажется меньше некоторого значения x , определяется функцией нормального распределения :
Используя математические свойства любого непрерывного распределения, несложно рассчитать и любые другие вероятности, так как
P(a ≤ X < b) = Ф(b) – Ф(a)
Стандартное нормальное распределение
Нормальное распределение зависит от параметров средней и дисперсии, из-за чего плохо видны его свойства. Хорошо бы иметь некоторый эталон распределения, не зависящий от масштаба данных. И он существует. Называется стандартным нормальным распределением . На самом деле это обычное нормальное нормальное распределение, только с параметрами математического ожидания 0, а дисперсией – 1, кратко записывается N(0, 1).
Любое нормальное распределение легко превращается в стандартное путем нормирования:
где z
– новая переменная, которая используется вместо x;
m
– математическое ожидание;
σ
– стандартное отклонение.
Для выборочных данных берутся оценки:
Среднее арифметическое и дисперсия новой переменной z теперь также равны 0 и 1 соответственно. В этом легко убедиться с помощью элементарных алгебраических преобразований.
В литературе встречается название z-оценка . Это оно самое – нормированные данные. Z-оценку можно напрямую сравнивать с теоретическими вероятностями, т.к. ее масштаб совпадает с эталоном.
Посмотрим теперь, как выглядит плотность стандартного нормального распределения (для z-оценок ). Напомню, что функция Гаусса имеет вид:
![]()
Подставим вместо (x-m)/σ букву z , а вместо σ – единицу, получим функцию плотности стандартного нормального распределения :
![]()
График плотности:

Центр, как и ожидалось, находится в точке 0. В этой же точке функция Гаусса достигает своего максимума, что соответствует принятию случайной величиной своего среднего значения (т.е. x-m=0 ). Плотность в этой точке равна 0,3989, что можно посчитать даже в уме, т.к. e 0 =1 и остается рассчитать только соотношение 1 на корень из 2 пи.
Таким образом, по графику хорошо видно, что значения, имеющие маленькие отклонения от средней, выпадают чаще других, а те, которые сильно отдалены от центра, встречаются значительно реже. Шкала оси абсцисс измеряется в стандартных отклонениях, что позволяет отвязаться от единиц измерения и получить универсальную структуру нормального распределения. Кривая Гаусса для нормированных данных отлично демонстрирует и другие свойства нормального распределения. Например, что оно является симметричным относительно оси ординат. В пределах ±1σ от средней арифметической сконцентрирована большая часть всех значений (прикидываем пока на глазок). В пределах ±2σ находятся большинство данных. В пределах ±3σ находятся почти все данные. Последнее свойство широко известно под названием правило трех сигм для нормального распределения.
Функция стандартного нормального распределения позволяет рассчитывать вероятности.
![]()
Понятное дело, вручную никто не считает. Все подсчитано и размещено в специальных таблицах, которые есть в конце любого учебника по статистике.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности ;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1 , т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.

В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец 0 , т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z) , т.е. плотность для 1 тождественна плотности для -1 , что отчетливо видно на рисунке.

Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z .
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения .
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:
Это факт показан на картинке:

Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z) . Получится равенство, указанное чуть выше.
Если нужно отыскать вероятность попадания в интервал (0; z) , то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:

Для наглядности можно взглянуть на рисунок.

На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z .

Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:

Рисунок ниже.

Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.

Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу.
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:

Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z : 1,64, 1,96 и 3.

Как понять смысл этих чисел? Начнем с z=1,64 , для которого табличное значение составляет 0,4495 . Проще всего пояснить смысл на рисунке.

То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от 0 до 1,64 , равна 0,4495 . При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.

Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64 , т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).

Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.

Еще одно интересное и часто используемое табличное значение соответствует z=3 , оно равно по нашей таблице 0,4986 . Умножим на 2 и получим 0,997 . Значит, в рамках ±3σ от средней арифметической заключены почти все значения.

Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.
Нормальное распределение в Excel
В Excel есть несколько функций для подсчета вероятностей или обратных значений нормального распределения.

Функция НОРМ.СТ.РАСП
Функция НОРМ.СТ.РАСП предназначена для расчета плотности ϕ(z ) или вероятности Φ(z) по нормированным данным (z ).
=НОРМ.СТ.РАСП(z;интегральная)
z – значение стандартизованной переменной
интегральная
– если 0, то рассчитывается плотность
ϕ(z
)
, если 1 – значение функции Ф(z), т.е. вероятность P(Z
Рассчитаем плотность и значение функции для различных z: -3, -2, -1, 0, 1, 2, 3 (их укажем в ячейке А2).
Для расчета плотности потребуется формула =НОРМ.СТ.РАСП(A2;0). На диаграмме ниже – это красная точка.
Для расчета значения функции =НОРМ.СТ.РАСП(A2;1). На диаграмме – закрашенная площадь под нормальной кривой.

В реальности чаще приходится рассчитывать вероятность того, что случайная величина не выйдет за некоторые пределы от средней (в среднеквадратичных отклонениях, соответствующих переменной z
), т.е. P(|Z|

Определим, чему равна вероятность попадания случайной величины в пределы ±1z, ±2z и ±3z от нуля. Потребуется формула 2Ф(z)-1 , в Excel =2*НОРМ.СТ.РАСП(A2;1)-1.

На диаграмме отлично видны основные основные свойства нормального распределения, включая правило трех сигм. Функция НОРМ.СТ.РАСП – это автоматическая таблица значений функции нормального распределения в Excel.
Может стоять и обратная задача: по имеющейся вероятности P(Z
Функция НОРМ.СТ.ОБР
НОРМ.СТ.ОБР рассчитывает обратное значение функции стандартного нормального распределения. Синтаксис состоит из одного параметра:
=НОРМ.СТ.ОБР(вероятность)
вероятность – это вероятность.
Данная формула используется так же часто, как и предыдущая, ведь по тем же таблицам искать приходится не только вероятности, но и квантили.

Например, при расчете доверительных интервалов задается доверительная вероятность, по которой нужно рассчитать величину z .

Учитывая то, что доверительный интервал состоит из верхней и нижней границы и то, что нормальное распределение симметрично относительно нуля, достаточно получить верхнюю границу (положительное отклонение). Нижняя граница берется с отрицательным знаком. Обозначим доверительную вероятность как γ (гамма), тогда верхняя граница доверительного интервала рассчитывается по следующей формуле.
![]()
Рассчитаем в Excel значения z (что соответствует отклонению от средней в сигмах) для нескольких вероятностей, включая те, которые наизусть знает любой статистик: 90%, 95% и 99%. В ячейке B2 укажем формулу: =НОРМ.СТ.ОБР((1+A2)/2). Меняя значение переменной (вероятности в ячейке А2) получим различные границы интервалов.

Доверительный интервал для 95% равен 1,96, то есть почти 2 среднеквадратичных отклонения. Отсюда легко даже в уме оценить возможный разброс нормальной случайной величины. В общем, доверительным вероятностям 90%, 95% и 99% соответствуют доверительные интервалы ±1,64, ±1,96 и ±2,58 σ.
В целом функции НОРМ.СТ.РАСП и НОРМ.СТ.ОБР позволяют произвести любой расчет, связанный с нормальным распределением. Но, чтобы облегчить и уменьшить количество действий, в Excel есть несколько других функций. Например, для расчета доверительных интервалов средней можно использовать ДОВЕРИТ.НОРМ. Для проверки о средней арифметической есть формула Z.ТЕСТ.
Рассмотрим еще пару полезных формул с примерами.
Функция НОРМ.РАСП
Функция НОРМ.РАСП отличается от НОРМ.СТ.РАСП лишь тем, что ее используют для обработки данных любого масштаба, а не только нормированных. Параметры нормального распределения указываются в синтаксисе.
=НОРМ.РАСП(x;среднее;стандартное_откл;интегральная)
среднее – математическое ожидание, используемое в качестве первого параметра модели нормального распределения
стандартное_откл – среднеквадратичное отклонение – второй параметр модели
интегральная
– если 0, то рассчитывается плотность, если 1 – то значение функции, т.е. P(X
Например, плотность для значения 15, которое извлекли из нормальной выборки с матожиданием 10, стандартным отклонением 3, рассчитывается так:

Если последний параметр поставить 1, то получим вероятность того, что нормальная случайная величина окажется меньше 15 при заданных параметрах распределения. Таким образом, вероятности можно рассчитывать напрямую по исходным данным.
Функция НОРМ.ОБР
Это квантиль нормального распределения, т.е. значение обратной функции. Синтаксис следующий.
=НОРМ.ОБР(вероятность;среднее;стандартное_откл)
вероятность – вероятность
среднее – матожидание
стандартное_откл – среднеквадратичное отклонение
Назначение то же, что и у НОРМ.СТ.ОБР , только функция работает с данными любого масштаба.
Пример показан в ролике в конце статьи.
Моделирование нормального распределения
Для некоторых задач требуется генерация нормальных случайных чисел. Готовой функции для этого нет. Однако В Excel есть две функции, которые возвращают случайные числа: СЛУЧМЕЖДУ и СЛЧИС. Первая выдает случайные равномерно распределенные целые числа в указанных пределах. Вторая функция генерирует равномерно распределенные случайные числа между 0 и 1. Чтобы сделать искусственную выборку с любым заданным распределением, нужна функция СЛЧИС .
Допустим, для проведения эксперимента необходимо получить выборку из нормально распределенной генеральной совокупности с матожиданием 10 и стандартным отклонением 3. Для одного случайного значения напишем формулу в Excel.
НОРМ.ОБР(СЛЧИС();10;3)
Протянем ее на необходимое количество ячеек и нормальная выборка готова.
Для моделирования стандартизованных данных следует воспользоваться НОРМ.СТ.ОБР.
Процесс преобразования равномерных чисел в нормальные можно показать на следующей диаграмме. От равномерных вероятностей, которые генерируются формулой СЛЧИС, проведены горизонтальные линии до графика функции нормального распределения. Затем от точек пересечения вероятностей с графиком опущены проекции на горизонтальную ось.
Наиболее известным и часто применяемым в теории вероятностей законом является нормальный закон распределения или закон Гаусса .
Главная особенность нормального закона распределения заключается в том, что он является предельным законом для других законов распределения.
Заметим, что для нормального распределения интегральная функция имеет вид:
 .
.
Покажем теперь, что вероятностный смысл параметров и таков: а есть математическое ожидание, - среднее квадратическое отклонение (то есть ) нормального распределения:
а) по определению математического ожидания непрерывной случайной величины имеем

Действительно
 ,
,
так как под знаком интеграла стоит нечётная функция, и пределы интегрирования симметричны относительно начала координат;
 - интеграл Пуассона
.
- интеграл Пуассона
.
Итак, математическое ожидание нормального распределения равно параметру а .
б) по определению дисперсии непрерывной случайной величины и, учитывая, что , можем записать
 .
.
Интегрируя по частям, положив  , найдём
, найдём

Следовательно ![]() .
.
Итак, среднее квадратическое отклонение нормального распределения равно параметру .
 |
В случае если и нормальное распределение называют нормированным (или, стандартным нормальным) распределением. Тогда, очевидно, нормированная плотность (дифференциальная) и нормированная интегральная функция распределения запишутся соответственно в виде:

(Функция , как вам известно, называется функцией Лапласа (см. ЛЕКЦИЮ5) или интегралом вероятностей. Обе функции, то есть ![]() , табулированы и их значения записаны в соответствующих таблицах).
, табулированы и их значения записаны в соответствующих таблицах).
Свойства нормального распределения (свойства нормальной кривой):
1. Очевидно, функция на всей числовой прямой.
2. ![]() , то есть нормальная кривая расположена над осью Ох
.
, то есть нормальная кривая расположена над осью Ох
.
3. ![]() , то есть ось Ох
служит горизонтальной асимптотой графика.
, то есть ось Ох
служит горизонтальной асимптотой графика.
4. Нормальная кривая симметрично относительно прямой х = а (соответственно график функции симметричен относительно оси Оу ).
Следовательно, можем записать : .
5.  .
.
6. Легко показать, что точки  и
и  являются точками перегиба нормальной кривой (доказать самостоятельно).
являются точками перегиба нормальной кривой (доказать самостоятельно).
7. Очевидно, что

но, так как  , то
, то ![]() . Кроме того
. Кроме того ![]() , следовательно, все нечётные моменты равны нулю.
, следовательно, все нечётные моменты равны нулю.
Для чётных же моментов можем записать:

8.  .
.
9.  .
.
10. ![]() , где .
, где .
11. При отрицательных значениях случайной величины: , где .
13. Вероятность попадания случайной величины на участок, симметричный относительно центра распределения, равна:

ПРИМЕР 3 . Показать, что нормально распределённая случайная величина Х отклоняется от математического ожидания М (Х ) не более чем на .
Решение
. Для нормального распределения: ![]() .
.

Другими словами, вероятность того, что абсолютная величина отклонения превысит утроенное среднее квадратическое отклонение, очень мала, а именно равна 0, 0027. Это означает, что лишь в 0,27% случаев так может произойти. Такие события, исходя из принципа невозможности маловероятных событий, можно считать практически невозможными.
Итак, событие с вероятностью 0,9973 можно считать практически достоверным, то есть случайная величина отклоняется от математического ожидания не более чем на .
ПРИМЕР 4 . Зная характеристики нормального распределения случайной величины Х - предела прочности стали: кг/мм 2 и кг/мм 2 , найти вероятность получения стали с пределом прочности от 31 кг/мм 2 до 35 кг/мм 2 .
Решение .
3. Показательное распределение (экспоненциальный закон распределения)
 |
Показательным (экспоненциальным) называют распределение вероятностей непрерывной случайной величины Х , которое описывается дифференциальной функцией (плотность распределения)

где - постоянная положительная величина.
Показательное распределение определяется одним параметром . Эта особенность показательного распределения указывает на его преимущество, по сравнению с распределениями, зависящими от большего числа параметров. Обычно параметры неизвестны и приходится находить их оценки (приближённые значения); разумеется, проще оценить один параметр, чем два, или три и т.д.
 |
Нетрудно записать интегральную функцию показательного распределения:

Мы определили показательное распределение при помощи дифференциальной функции; ясно, что его можно определить, пользуясь интегральной функцией.
Замечание
: Рассмотрим непрерывную случайную величину Т
- длительность времени безотказной работы изделия. Обозначим принимаемые её значения через t
, . Интегральная функция распределения ![]() определяет вероятность отказа
изделия за время длительностью t
. Следовательно, вероятность безотказной работы за это же время, длительностью t
, то есть вероятность противоположного события , равна
определяет вероятность отказа
изделия за время длительностью t
. Следовательно, вероятность безотказной работы за это же время, длительностью t
, то есть вероятность противоположного события , равна
Случайные величины связаны со случайными событиями. О случайных событиях говорят тогда, когда оказывается невозможным однозначно предсказать результат, который может быть получен в тех или иных условиях.
Предположим, мы бросаем обыкновенную монету. Обычно результат этой процедуры не является однозначно определенным. Можно лишь с уверенностью утверждать, что произойдет одно из двух: либо выпадет "орел", либо "решка". Любое из этих событий будет случайным. Можно ввести переменную, которая будет описывать исход этого случайного события. Очевидно, что эта переменная будет принимать два дискретных значения: "орел" и "решка". Поскольку мы заранее точно не можем предугадать, какое из двух возможных значений примет эта переменная, можно утверждать, что в этом случае мы имеем дело со случайными величинами.
Предположим теперь, что в эксперименте мы проводим оценку времени реакции испытуемого при предъявлении какого-либо стимула. Как правило, оказывается, что даже тогда, когда экспериментатор предпримет все меры к тому, чтобы стандартизировать экспериментальные условия, минимизировав или даже сведя к нулю возможные вариации в предъявлении стимула, измеренные величины времени реакции испытуемого все равно будут различаться. В таком случае говорят, что время реакции испытуемого описывается случайной величиной. Поскольку в принципе в эксперименте мы можем получить любое значение времени реакции – множество возможных значений времени реакции, которые можно получить в результате измерений, оказывается бесконечным, – говорят о непрерывности этой случайной величины.
Возникает вопрос: существуют ли какие-либо закономерности в поведении случайных величин? Ответ на этот вопрос оказывается утвердительным.
Так, если провести бесконечно большое число подбрасываний одной и той же монеты, можно обнаружить, что число выпадений каждой из двух сторон монеты окажется примерно одинаковым, если, конечно, монета не фальшивая и не гнутая. Чтобы подчеркнуть эту закономерность, вводят понятие вероятности случайного события. Ясно, что в случае с подбрасыванием монеты одно из двух возможных событий произойдет непременно. Это обусловлено тем, что суммарная вероятность этих двух событий, иначе называемая полной вероятностью, равна 100%. Если предположить, что оба из двух событий, связанных с испытанием монеты, происходят с равными долями вероятности, то вероятность каждого исхода в отдельности, очевидно, оказывается равной 50%. Таким образом, теоретические размышления позволяют нам описать поведение данной случайной величины. Такое описание в математической статистике обозначается термином "распределение случайной величины" .
Сложнее обстоит дело со случайной величиной, которая не имеет четко определенного набора значений, т.е. оказывается непрерывной. Но и в этом случае можно отметить некоторые важные закономерности ее поведения. Так, проводя эксперимент с измерением времени реакции испытуемого, можно отметить, что различные интервалы длительности реакции испытуемого оцениваются с разной степенью вероятности. Скорее всего, редко, когда испытуемый будет реагировать слишком быстро. Например, в задачах семантического решения испытуемым практически не удается более или менее точно реагировать со скоростью менее 500 мс (1/2 с). Аналогично маловероятно, что испытуемый, добросовестно следующий инструкциям экспериментатора, будет сильно затягивать свой ответ. В задачах семантического решения, например, реакции, оцениваемые более чем 5 с, обычно рассматриваются как недостоверные. Тем не менее со 100%-ной уверенностью можно предполагать, что время реакции испытуемого окажется в диапазоне от О до +со. Но эта вероятность складывается из вероятностей каждого отдельного значения случайной величины. Поэтому распределение непрерывной случайной величины можно описать в виде непрерывной функции у = f (х ).
Если мы имеем дело с дискретной случайной величиной, когда все возможные ее значения заранее известны, как в примере с монетой, построить модель ее распределения, как правило, оказывается не очень сложным. Достаточно ввести лишь некоторые разумные допущения, как мы это сделали в рассматриваемом примере. Сложнее обстоит дело с распределением непрерывных величии, принимающих заранее неизвестное число значений. Конечно, если бы мы, например, разработали теоретическую модель, описывающую поведение испытуемого в эксперименте с измерением времени реакции при решении задачи семантического решения, можно было бы попытаться на основе этой модели описать теоретическое распределение конкретных значений времени реакции одного и того же испытуемого при предъявлении одного и того же стимула. Однако такое не всегда оказывается возможным. Поэтому экспериментатор бывает вынужденным предположить, что распределение интересующей его случайной величины описывается каким-либо уже заранее исследованным законом. Чаще всего, хотя это, возможно, и не всегда оказывается абсолютно корректным, для этих целей используется так называемое нормальное распределение, выступающее в качестве эталона распределения любой случайной величины независимо от ее природы. Это распределение впервые было описано математически еще в первой половине XVIII в. де Муавром.
Нормальное распределение имеет место тогда, когда интересующее нас явление подвержено влиянию бесконечного числа случайных факторов, уравновешивающих друг друга. Формально нормальное распределение, как показал де Муавр, может быть описано следующим соотношением:
где х представляет собой интересующую нас случайную величину, поведение которой мы исследуем; Р – значение вероятности, связанное с этой случайной величиной; π и е – известные математические константы, описывающие соответственно отношение длины окружности к диаметру и основание натурального логарифма; μ и σ2 – параметры нормального распределения случайной величины – соответственно математическое ожидание и дисперсия случайной величины х.
Для описания нормального распределения оказывается необходимым и достаточным определение лишь параметров μ и σ2.
Поэтому если мы имеем случайную величину, поведение которой описывается уравнением (1.1) с произвольными значениями μ и σ2, то можем обозначить его как Ν (μ, σ2), не держа в памяти всех деталей этого уравнения.

Рис. 1.1.
Любое распределение можно представить наглядно в виде графика. Графически нормальное распределение имеет вид колоколообразной кривой, точная форма которой определяется параметрами распределения, т.е. математическим ожиданием и дисперсией. Параметры нормального распределения могут принимать практически любые значения, которые оказываются ограничены лишь используемой экспериментатором измерительной шкалой. В теории значение математического ожидания может равняться любому числу из диапазона чисел от -∞ до +∞, а дисперсия – любому неотрицательному числу. Поэтому существует бесконечное множество различных видов нормального распределения и соответственно бесконечное множество кривых, его представляющих (имеющих, однако, сходную колоколообразную форму). Понятно, что все их описать невозможно. Однако, если известны параметры конкретного нормального распределения, его можно преобразовать к так называемому единичному нормальному распределению, математическое ожидание для которого равно нулю, а дисперсия – единице. Такое нормальное распределение называют еще стандартным или z-распределением. График единичного нормального распределения представлен на рис. 1.1, откуда очевидно, что вершина колоколообразной кривой нормального распределения характеризует величину математического ожидания. Другой параметр нормального распределения – дисперсия – характеризует степень "распластанности" колоколообразной кривой относительно горизонтали (оси абсцисс).